Les travailleurs du clic et l’intelligence artificielle

La prophétie d’une intelligence artificielle autonome et anthropomorphe est ancrée dans l’imaginaire collectif depuis des décennies, impulsée par une culture largement romancée et les effets d’annonces des acteurs du secteur. Pourtant, dans les coulisses, se cache encore un travail humain. Une multitude de petites mains nourrissent les machines de précieuses données et entraînent les algorithmes. Micro travail, ouvriers du clic, crowdworking, digital labor, microtasking, autant de termes qui définissent cette nouvelle catégorie de travailleurs peu connue et loin d’être anecdotique. Ils accomplissent des tâches multiples et d’une simplicité déconcertante, paradoxalement essentielles à l’apprentissage des machines. Ce marché en pleine expansion pourrait inclure 213 millions de travailleurs en 2019 au niveau mondiale selon l’Organisation Internationale du Travail (OIT). Toutefois, les travailleurs du clic sont soigneusement dissimulés, entretenant ainsi le mythe de “l’intelligence artificielle” et la précarité de leur métier. Partant de ce constat, l’OIT a publié en septembre 2018 un rapport d’étude dans lequel elle appelle à un encadrement urgent de cette pratique obéissant à un nouveau business model encore en marge des normes habituelles du travail.
Au-delà de cette nouvelle profession, les utilisateurs de plateformes de réseaux sociaux eux-mêmes nourrissent la machine dans l’ignorance la plus complète. Ainsi l’été dernier, dans le cadre d’une exposition à Paris sur l’intelligence artificielle et l’art, Google a invité ses visiteurs à tester le dispositif #DrawToArt qui proposait aux utilisateurs de faire un dessin afin que l’IA de Google identifie l’œuvre lui ressemblant le plus. Faisant par la même occasion faire au public un travail du clic gratuit. Il en est de même pour le “10yearchallenge” apparut à la fin de l’année 2018 sur les réseaux sociaux, pouvant permettre d’améliorer significativement les systèmes de reconnaissance faciale sur la prédiction du vieillissement.
Dès lors, il s’agit de déconstruire le mythe d’un robot omniscient, d’un « bluff technologique » dénoncé par Antonio Casilli dans son ouvrage « en attendant les robots : enquête sur le travail du clic », afin de mettre en lumière des travailleurs précarisés, fragilisés par cette invisibilité.
La face cachée de l’Intelligence Artificielle, les travailleurs “invisibles” du clic :
Loin de l’illusion d’une intelligence artificielle douée de conscience, l’IA n’en est en réalité qu’à ses balbutiements et ne parvient pas encore à réellement simuler l’intelligence humaine. En effet, les algorithmes d’IA actuels reposent principalement sur deux types d’apprentissages. Tout d’abord le machine learning qui correspond à un apprentissage automatique ou statistique à partir de jeux de données. Cet apprentissage peut être supervisé, semi-supervisé ou non supervisé. Puis le deep learning, qui est une forme d’apprentissage automatique, où les algorithmes s’entraînent notamment à reconnaître des visages, des objets ou encore à traduire des textes, grâce à une superposition de plusieurs réseaux de neurones.
Ainsi, l’IA actuelle est souvent confondue à tort avec l’IA forte, alors qu’elle est encore loin d’avoir cette capacité à appliquer son intelligence à n’importe quel type de problématique. Par exemple, l’IA AlphaGo a réussi à battre l’humain dans l’un des derniers bastions de l’intelligence naturelle, toutefois cette IA est incapable de différencier un chat d’un chien, chose que tout enfant de 5 ans fait naturellement. C’est à cette étape qu’interviennent les ouvriers du clic, dont le travail consiste à enrichir les bases de données des machines, en réalisant un tri ou en affinant l’information qui sera ensuite traitée, entretenant ainsi le mythe de la machine omnipotente.
Selon Antonio Casilli, ce digital labor se définit comme « toute activité qui produit de la valeur et qui est fondé sur des principes de tâcheronisation et de datafication ». La tâcheronisation correspond à une fragmentation du travail en tâches standards les plus simples possibles. Le principe de datafication quant à lui est un travail fondé sur un flux constant de données générées et exploitées. Les travailleurs du clic accomplissent donc des tâches telles que l’écoute de conversation, la transcription de texte, le visionnage de vidéo ou répondent à des questionnaires.
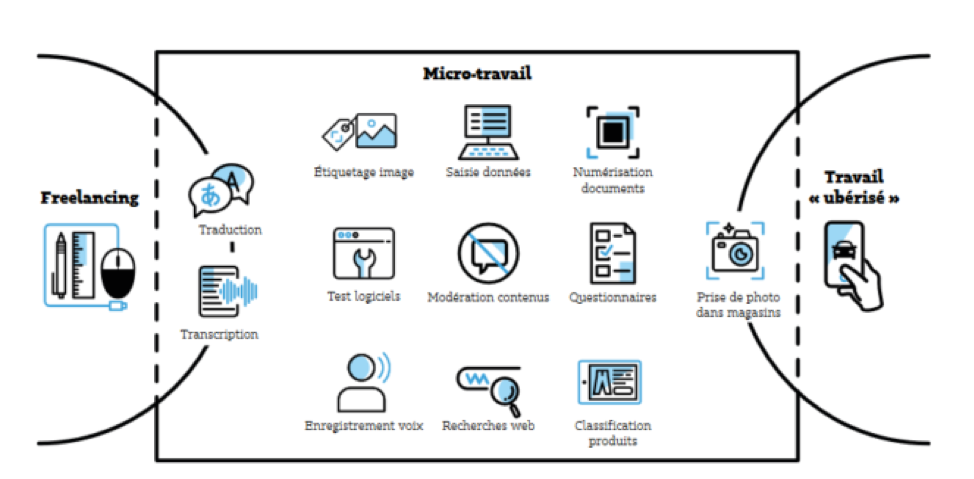
De plus, l’auteur distingue trois grandes familles de travailleurs du clic :
- Le « travail à la demande », forme la plus familière, où l’on passe par une application de travail à flux tendu afin d’avoir accès à un service. C’est le cas par exemple d’Uber ou Deliveroo.
- Le « micro-travail », bien moins connu, englobe toutes les tâches fragmentées réalisées via des plateformes par une foule de travailleurs micro-rémunérés.
- Le « travail gratuit » correspond au travail accompli par les utilisateurs de réseaux sociaux ou de moteur de recherche. Il revient à réaliser des tâches d’étiquetage gratuitement, sans s’en rendre compte, tel que l’identification de personnes ou de lieux sur des photos.
Ce sont ces deux dernières catégories qui jouent un rôle invisible dans l’apprentissage de l’intelligence artificielle.
En outre, le travail du clic se fonde essentiellement sur un nouveau business model, le crowdsourcing, c’est-à-dire :
“The act of taking a job once performed by a designated agent (an employee, freelancer or a separate firm) and outsourcing it to an undefined, generally large group of people through the form of an open call, which usually takes place over the Internet” (Howe, quoted in Safire, 2009; see also Howe, 2006).
Cette pratique a ainsi permis à un maximum de personnes, qualifiées ou non, d’accéder à des offres de micro-travail via des plateformes.
Plateformes du digital labor, la menace fantôme :
À l’instar des grandes familles de travailleurs du clic, il existe différents types de plateformes permettant ou forçant le travail du clic.
- Les plateformes de réservation de services auprès d’auto-entrepreneurs, qui bien que contestables ne sont pas le sujet de ce blog ;
- Les plateformes ou sites internet utilisant des mécanismes du type recaptcha ou similaires ; et
- Les plateformes ou places de marché offrant des contrats de micro-travail du clic.
Depuis 2009, date à laquelle Google s’est approprié les travaux de chercheurs de l’Université Carnegie Mellon, le travail dissimulé, forcé et non-rémunéré est devenue chose courante pour l’ensemble des internautes. En effet, en 2007 des universitaires ont eu l’idée d’associer les utilisateurs devant prouver qu’ils sont humains à des données qui doivent être transcrites, afin que cela soit bénéfique pour tous en créant le système captcha (Completely Automated Public Turing test to tell Computers and Humans Apart). Google en a profité pour utiliser des millions de personnes qui, sans le savoir, ont collaboré pour atteindre le même objectif : numériser les archives de Google Books. Les recaptcha ont commencé à pulluler sur des milliers de sites internet majeurs tout en conditionnant l’accès à ceux-ci. En 2011, collectivement les internautes avaient fini de numériser 20 millions de livres ainsi que 13 millions d’articles des archives du New York Times. Le tout à la main, sans le savoir, en pensant devoir prouver leur humanité.
En 2015, une américaine avait porté plainte contre Google en l’accusant de détourner le service de captcha à son avantage. Toutefois la plaignante n’a pas eu gain de cause car elle n’a pas réussi à prouver le préjudice économique subi, ni une quelconque forme de tromperie de la part du géant du numérique. Ce jugement est critiquable pour un certain nombre de raisons, notamment sur son absence de prise en compte du travail, effectué chaque jour gratuitement et à leur insu, par des millions d’internautes pour le bénéfice d’entreprises privées. Et pourtant, “Jure naturae aequum est, neminem cum alterius detrimento, et injuria fieri locupletiorem”. Cette maxime latine signifiant qu’il est d’équité naturelle que nul ne doit s’enrichir au détriment et au préjudice d’autrui aurait pourtant vocation à s’appliquer aux plateformes et sites internet utilisant les systèmes de captcha.
Plus récemment, le système des captcha s’est développé pour demander aux internautes de reconnaître des ponts, des feux, des bornes à incendie, des panneaux de signalisation, des devantures de magasin, ce afin de nourrir des bases de données utilisées par des entreprises telles Uber, Amazon, Google, etc., pour nourrir leurs algorithmes utilisés dans les voitures autonomes et autres outils d’intelligence artificielle. Pour appréhender l’étendue du travail fourni par les internautes, il est important de comprendre comment fonctionne l’apprentissage automatique. Il faut donner à l’algorithme un nombre conséquent de données qui sont déjà triées – par exemple, un tas d’images de panneaux signalisation que marquées comme tels par les internautes, puis l’algorithme utilise cette information pour construire un réseau neuronal qui lui permet de sélectionner les panneaux de signalisation dans d’autres images. Plus il y a d’images étiquetés, plus l’IA devient précise dans la sélection des panneaux de signalisation à partir d’autres images.
Au Québec, l’enrichissement injustifié est définit par l’article 1493 du Code civil comme étant une personne qui s’enrichit grâce à une autre personne sans qu’il existe de justification à cet enrichissement. Toutefois pour que la personne enrichie ait à indemniser la seconde, il est nécessaire de prouver un appauvrissement corrélatif de celle-ci. Or dans un système de travail du clic, bien qu’il n’existe aucune justification à l’enrichissement d’entreprises grâce aux actions de millions de personnes non-salariées, il est extrêmement compliqué de prouver l’appauvrissement d’un individu qui fractionne chaque jour son temps d’étiquetage de données. De même qu’il est compliqué de prouver l’appauvrissement corrélatif de la société canadienne dans son ensemble, car un meilleur étiquetage permet de constituer rapidement de plus grandes bases de données, nécessaires à l’entraînement des algorithmes afin de les perfectionner et limiter leurs erreurs. Ce qui bénéficiera à terme aux citoyens. Toutefois il semble nécessaire de trouver une solution, à l’instar des logiciels contaminants, qui permettent d’étendre le statut des œuvres créées sous cette licence à toute création réalisée dérivé de la première. Ainsi cela empêche les entreprises de bénéficier du travail d’autrui pour leurs profits personnels.
Nous pourrions nous inspirer des initiatives, bien que critiquables sur certains points, de groupes comme Amazon, qui a monté le Amazon Mechanical Turk. Ce service se définit comme une plateforme de crowdsourcing qui permet aux particuliers et aux entreprises d’externaliser plus facilement leurs processus et leurs tâches à une main-d’œuvre répartie qui peut effectuer ces tâches virtuellement. Il offre aux développeurs l’accès à une main-d’œuvre à la demande. Le travail est organisé selon un système de rémunération à la tâche dans lequel les travailleurs sont payés pour chaque tâche accomplie avec succès. La plateforme regroupe environ 100.000 personnes selon les derniers chiffres publiés par un groupe de chercheurs en 2018. D’autres comme Clickworker, vantent plus de 1.5 millions de travailleurs du clic enregistrés sur leur plateforme. Ces mêmes chercheurs estiment par ailleurs que les travailleurs du clic gagnent en moyenne 2$USD de l’heure. Principalement à cause du travail non-payé relié à la tâche, qui impacte le taux horaire. Ce travail non payé se scinde en trois éléments : la recherche de tâche, les tâches commencées mais non complétées et les tâches accomplies mais rejetées par le commanditaire.
Ces exemples apportent une lumière inquiétante sur le travail du clic à une époque où les algorithmes sont toujours plus voraces. Cette montée de la tâcheronisation, dénoncée par Casilli, semble être la regrettable continuité d’une uberisation de la force de travail, dans un contexte transnational où le droit est souvent bafoué.
Marx 4.0 ou l’avènement d’un “cyber-prolétariat” :
Le digital labor n’est en fait qu’une représentation des mutations économiques et salariales induites par l’avènement des nouvelles technologies : la gig economy ou économie à la tâche. Réel bouleversement ou retour au taylorisme du siècle passé, il reste que les travailleurs du clic baignent dans un océan d’incertitudes qui ne fait qu’accroître leur précarisation, ce que le professeur Casilli qualifie de “cyber-prolétariat”.

Les facteurs essentiels de cette vulnérabilité sont :
- Une précarité salariale conséquente.
- Un manque de compréhension important des conditions d’utilisation des plateformes de crowdsourcing, d’autant plus pour les travailleurs issus de régions en voie de développement où l’accès au conseil juridique tient souvent du parcours du combattant. Ces contrats d’adhésion imposés par les plateformes sont indigestes, complexes et tendent à protéger leurs intérêts propres.
- Un impact psychologique, en raison d’une dépendance à un système de recherche de missions par alerte, ainsi qu’à des tendances dépressives dues à une exposition répétée à des images violentes.
- L’opacité dans le fonctionnement des plateformes. Par exemple, AMT permet aux travailleurs mieux notés d’accéder à plus de missions mieux rémunérées réparties selon un algorithme interne.
- Des difficultés à définir le statut juridique de ces travailleurs et, a fortiori, les droits en découlant.
L’on fait donc face à une classe de travailleurs précaires, qui participent à l’économie mondiale du numérique grâce à trois outils, une connexion internet, leur ordinateur et leur souris. Toutefois ces cyber-prolétaires, à l’inverse des prolétaires en sens marxiste du terme, ne bénéficient pas à l’heure actuelle de la protection que peut apporter le salariat. Ils sont des contractuels qui travaillent de manière autonome, qui font appel à des structures pour leur fournir des mandats rémunérés sans toutefois bénéficier des avantages sociaux. En effet, le travailleur autonome travaille à son propre compte et effectue ses missions en tant que prestataire de service indépendant ou sous-traitant. Il est de facto souvent dans une situation précaire en raison de périodes de travail aléatoires et d’un maigre salaire.
Toutefois le cyber-prolétariat autonome n’est pas une fatalité. Dans une affaire notable (arrêt C-434/17, 20 décembre 2017, la CJUE a requalifié la plateforme d’intermédiation Uber en prestataire de service de transport, permettant à la Cour d’appel de Paris de requalifier le contrat de prestation de service d’un chauffeur Uber en un contrat de travail. Selon les juges, le contrat de travail suppose un lien de subordination, caractérisé par les pouvoirs cumulés de direction, de contrôle et de sanction. Dans ce domaine, la qualification donnée au contrat par les parties ou leur volonté lors de la conclusion de celui-ci importe peu. De sorte que les juges ont déterminé qu’un chauffeur Uber pouvait être qualifié de travailleur indépendant, à savoir une personne qui :
- Constitue une clientèle propre ;
- Fixe librement ses tarifs ;
- Fixe librement les conditions d’exercice de sa prestation.
Cette requalification des chauffeurs Uber en travailleurs indépendant emporte une multitude d’obligations et droits tels que l’application du code du travail, la responsabilité juridique du transporteur ou encore le droit aux cotisations sociales.
Au Québec, pour déterminer si un travailleur du clic est considéré en tant que travailleur autonome, la jurisprudence a dégagé certains critères. Le travailleur autonome :
- Contrôle son travail;
- Fournit ses propres outils;
- Est exposée aux profits;
- Est exposée aux pertes.
Au regard de ces critères, les plateformes offrant du travail aux travailleurs du clic pourraient être requalifiées en employeurs dans la mesure où elles exercent un réel contrôle sur ces cyber-prolétaires, en les privant de la libre fixation de leurs tarifs et de déterminer leurs conditions d’exercice auprès des clients finaux.
A l’aube d’un encadrement juridique ?
A ce jour, plusieurs initiatives ont été prises afin d’encourager les différents acteurs du domaine à améliorer les conditions de travail.
Des site web, tels que Turkopticon ou FairCrowdWork, ont été développés ces dernières années. Leur but est la mise en place d’évaluations détaillées des plateformes, des travailleurs et des commanditaires. En 2014, une étude indépendante a révélé l’importance que les travailleurs et les commanditaires accordent à ces évaluations en ce qu’elles permettent aux ouvriers du clic d’avoir un meilleur contrôle sur leur travail, leur réputation et plus de transparence sur la paie et les tâches à accomplir. Notons tout de même que ces évaluations sont réalisées par l’intermédiaire des plateformes elles-mêmes, les travailleurs ne s’expriment donc pas librement. De plus, des guides et codes de conduites ont été mis en place, tel The dynamo guideline, à l’intention des commanditaires universitaires, ou The Corwdsourcing Code of Conduct pour les plateformes. Les plateformes signataires de ce code de conduites ont également mis en place un “Bureau de médiation” en vue de résoudre les litiges entre travailleurs et plateformes. Une fois adoptés, ces guides permettraient d’instaurer une base de travail juste et équitable pour ces travailleurs.
En outre, à la lumière de son étude, l’OIT a fait œuvre créatrice en dégageant 18 critères en vue d’assurer un travail décent sur les plateformes de travail numérique. Ces critères répondent aux faiblesses de la pratique actuelle telles que le manque de communication, de transparence, de bien-être et de droits pour les travailleurs du clic. Ils incluent notamment l’application du salaire minimum légal en vigueur dans l’Etat de travail du crowdworker ou la consécration d’un statut juridique pour ce type d’emploi. Plus largement, ces critères manifestent une volonté d’amoindrir le pouvoir de contrainte des commanditaires et des plateformes ainsi que le déséquilibre qui en résulte.
Bien qu’il s’agisse là d’efforts prometteurs, ces initiatives restent à nuancer. Il appert que ce sont plutôt les plateformes elles-mêmes qui fixent aujourd’hui ces nouvelles modalités, conservant ainsi leur force de contrainte. De plus, ces codes de conduites développés de façon indépendante sont basés sur le volontariat des plateformes à l’appliquer ou non. Par ailleurs, les critères dégagés par l’OIT ne revêtent bien sûr pas de valeur contraignante. En outre, s’agissant du travail du clic « gratuit », aucune législation ne permet encore d’encadrer ces pratiques.
Le levier clé de l’amélioration des conditions de travail des crowdworkers serait en fait les conditions d’utilisations des plateformes (Terms of Services). Celles-ci contiennent des dispositions ayant une incidence directe sur les conditions de travail telles que la maîtrise des comptes utilisateurs, la rémunération et l’évaluation des travailleurs ou plus généralement les droits des travailleurs. C’est par le biais de la modification de ces conditions d’utilisation et une meilleure appréhension par les travailleurs du clic de celles-ci que l’amélioration pourra être la plus notable.
Dans une approche prospective, les législations nationales pourraient ainsi mettre en place des standards juridiques, une base de principes communs, un ersatz de droits, concernant les conditions d’utilisation des plateformes entrant alors dans leur giron législatif. Or nous l’avons vu précédemment, les conditions d’utilisation des plateformes sont des contrats d’adhésion longs et complexes.
Cependant, il ne faut pas sous-estimer le défi que représente la réglementation du crowdworking, un métier évolutif qui est difficilement appréhendé par les normes traditionnelles du travail. Ainsi, si d’aucuns soutiennent à raison que ces initiatives ne suffiront pas à encadrer les dérives de cette activité, elles ont tout au moins le mérite de lancer une dynamique dialogique entre les différents antagonistes, saisissant la réalité des pratiques et suivant son évolution. De ce fait l’on dépose une première empreinte de juridicité sur le digital labor.
A propos des auteurs :
Laetitia Dimanche, étudiante en master 2 Cyberjustice à l’université de Strasbourg et assistante de recherche au laboratoire de Cyberjustice, a conduit des travaux de recherche dans les domaines des nouvelles technologies tels que l’intelligence artificielle. Elle est en outre spécialisée en droit international public et en droit spatial.
Erwan Jonchères, avocat au barreau du Québec, agent de recherche au Laboratoire de Cyberjustice, conduit des travaux de recherche sur la blockchain, la protection des données et l’intelligence artificielle. Il se spécialise dans le domaine de la résolution des conflits au sein des blockchain et des contrats intelligents.
This content has been updated on 26 February 2020 at 14 h 48 min.